There was a recent report about how many students were taking AP CS exams, breaking out the information by gender, race, and state, which has been released in a few different forms. Mark Guzdial’s blog post provides pointers to the data collected by Barbara Ericson. Some of the comments provided on that post shows an appalling lack of statistical reasoning (like comparing states by subtracting percentages of different things).
So what are the interesting questions to ask of the data and how should they be handled statistically?
Most of the “gee-whiz” statements are about how few people in some group or other took (or passed) the AP CS exam:
- No females took the exam in Mississippi, Montana, and Wyoming.
- 11 states had no Black students take the exam: Alaska, Idaho, Kansas, Maine, Mississippi, Montana, Nebraska, New Mexico, North Dakota, Utah, and Wyoming.
Some people pointed out that some of these numbers may not be more than a small sample effect (no one took the exam in Wyoming, so having zero female test takers is not surprising). How can we best state that a number is interesting?
Generally , this is done by creating a null model—one that computes the probability of different outcomes based on everything except the hypothesis being tested. Then you look at how surprising the observed outcome is given the null model. Exactly how the null model is constructed is crucial, as all that the statistical tests tell you is how badly your null model fits the data.
What sort of mathematical model should we be using for assigning probabilities to numbers of test takers (or numbers passing the test)? One convenient one is a binomial distribution. The binomial distributions are a family of distributions over non-negative integers with two parameters N and p. They are good for modeling the count of a number of independent events each of which occurs with some fixed probability. If we think of each high school student in a state as having some (small) probability of taking the exam, then the number of exam takers can be modelled as a binomial distribution whose N value is the number of students and p the probability that each one takes the exam. When N is large (as it would be for the number of high school students in a state) and Np is reasonably large, then the binomial distribution can be approximated by a normal distribution with mean Np and variance Np(1-p), but an even better approximation is to use the Poisson distribution with mean Np, which is what I’ll use here. The probability of zero test takers: 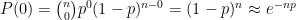
So all we need to set the parameters of our null model is an expected number of test takers based on everything except what we wanted to test. For example, if we wanted to test whether black test takers were under-represented in Maine, we would need a model that predicted how many black students would take the test, perhaps using the probability that students in Maine would take the test independent of race and the fraction of students in Maine that are black. For Maine, there were 161 test takers, and 0 black test takers. I don’t know the racial mix of high school students in Maine, but Wikipedia gives the black fraction of the whole state population as 1.03%. Thus the expected number of black test takers is 1.658, and we can use 
UPDATE: 2014 Feb 1. Some values in the following table corrected, due to clerical errors in copying from spreadsheet (I’m not sure which I hate worse, spreadsheets or HTML tables—they’re both awful formats).
| state | # test takers | state % black | expected black test takers | under-rep p< |
|---|---|---|---|---|
| Alaska | 21 | 4.27% | 0.897 | 0.41 |
| Idaho | 0.95% | |
||
| Kansas | 6.15% | |
|
|
| Maine | 161 | 1.03% | 1.658 | 0.19 |
| Mississippi | 37.3% | |
|
|
| Montana | 0.67% | |
|
|
| Nebraska | 4.50% | |
||
| New Mexico | 2.97% | |||
| North Dakota | 1.08% | |||
| Utah | 1.27% | |||
| Wyoming | 1.29% |
Even before we do a correction for having 51 hypotheses (50 states plus District of Columbia), none of these “no black students” states shows significant under-representation of black students. In fact, it would have been significantly surprising if the test taker in North Dakota had been black. None of the states had so few students that a black test taker would have been surprising (except Wyoming).
One can do similar computations to show that the lack of women in Mississippi, Montana, and Wyoming is not surprising. Montana looks surprising if treated as a single hypothesis (p<0.004), but not after multiple-hypothesis correction (E-value=0.21). Even combining all three states (which increases the number of hypotheses enormously and would call for a stronger multiple-hypothesis correction), the under-representation of women in those states is not statistically significant.
There are states that do have significant under-representation of women: for example, Utah had 103 test takers, only 4 of whom were women. With an expected number of about 51.5, this is p<1.4E-16. Even with 51× multiple hypothesis correction, this under-representation is hugely significant. Looking nationwide, total counts were 5485 female test takers out of 29555 total test takers. That’s p< 1.4E-1677. The highest percentage of female test takers was in Tennessee, with 73 out of 251, which is p< 2.6E-7, again highly significant.
Tennessee also had a high proportion of black test takers with 25 out of 251. With an expected number of 42.12, this is p<0.003 (still significantly under-represented). To see if black students were under-represented nationwide, one would have to add up the expected numbers for each state and see how the actual number compared with the expected number. (I’m certain that the under-representation is hugely significant since even the states with high numbers of black test takers are under-represented, but I’m too lazy to do the multiplication and addition needed.)
The case can clearly be made for female and black students being under-represented, though pointing to the states with 0 female or 0 black test takers is not the way to do it. (From a marketing standpoint, rather than a statistical one , shouting “no black test takers in these states”, “no female test takers in these other states” may be exactly the right way to get attention, even though the real story about blacks and females is in the states where there were enough test takers to say something about them after dividing them into subgroups.)
A case could also be made for some states having far fewer CS AP test takers than others. One would need to come up with an expected number of test takers from some model (for example, by state population as a share of national population, or by number of total AP test takers in state as share of national total AP test takers). The second model would correct for state-to-state differences in age distribution or in popularity of AP exam taking in general. One could also base predictions on some other STEM test, such as AP Calculus, if one wanted to control for different amounts of STEM instruction in different states.
Let’s look at the states with no black test takers again, to see if they are significantly under-represented in CS. There were 29555 AP CS tests taken nationwide and 3,824,691 AP tests nationwide total, so we would expect the CS tests taken in a state to be 0.77% of the total for the state.
| state | # CS test takers | # all test takers | expected CS test takers | p < | E-value |
|---|---|---|---|---|---|
| Alaska | 21 | 4570 | 35.31 | 0.0066 | 0.34 |
| Idaho | 9723 | 75.13 | |||
| Kansas | 15339 | 118.53 | |||
| Maine | 161 | 14051 | 108.58 | 0.9999 | |
| Mississippi | 9032 | 69.79 | |||
| Montana | 4868 | 37.62 | |||
| Nebraska | 11117 | 85.91 | |||
| New Mexico | 13365 | 103.28 | |||
| North Dakota | 2295 | 17.73 | |||
| Utah | 35721 | 276.03 | |||
| Wyoming | 2050 | 15.84 |
Of these eleven states, eight appear to be under-represented in CS test takers (Maine is significantly over-represented in CS test takers). When I do the multiple-hypothesis correction for having 51 different “states” (including the District of Columbia), the mild under-representation in Alaska and North Dakota is no longer significant, but the other nine eight are.
So the zero black AP CS test takers for the nine states can be fairly confidently attributed to the lack of AP CS test takers, and in Maine to the shortage of black students. For Alaska, the lack of black AP CS test takers is probably due to the shortage of AP CS test takers in the state.
One can generalize the techniques here to any method of predicting the mean number of students in some category, to see whether the observed number is significantly smaller than the predicted number. When the predicted number is small, even 0 students may not be statistically significant under-representation.

")
 or hardback ($198)")


[…] data, but not all of it has been particularly well-informed. We both really enjoyed reading the Gas Station Without Pumps analysis, quoted and linked below. Not only is it a careful, model-based analysis, but it’s a nice […]
Pingback by A careful model-based analysis of AP CS 2013 exam data: CS commenters need to learn statistics | Computing Education Blog — 2014 January 18 @ 13:12 |
Just curious: why is multiple-hypothesis correction (for 51 “states”) needed in this situation? I would have thought that each state’s data is independent of the other states’ data, and hence there are 51 independent tests (I’d have understood having to correct for a test on race, test on gender, etc per state). I’m still learning statistical methods, so this (useful!) post has me wondering what I’m missing on this issue. Thanks!
Kathi
Comment by Kathi Fisler — 2014 January 19 @ 10:49 |
If you are asking the question “does Illinois have under-representation?” then there is only one hypothesis being tested.
But if you are asking “Do states have under-representation?” and pull out the states with the lowest stats, then you are asking 51 different questions, and need stronger evidence to claim that the there is under-representation. It is the standard search problem that trips up a lot of biologists in modern high-throughput biology: if you examine 10,000 genes for over-expression, some of them will appear over-expressed just by chance due to the noise in the data. You need a strong enough signal to separate it from the random noise. The E-value is a (somewhat conservative) way of doing this correction—it is the expected number of states that look this bad just by chance. The E-value correction is similar to the Bonferroni correction, but easier to explain to biologists, and easier to interpret when you are looking for enrichment rather than proof (it is much easier to explain that we expected to find about 10 this good by chance than the probability that this arose by chance is 0.9999).
All the corrections you mentioned (for racial composition of the state, age distribution, socioeconomic status, …) come in the model for how many test takers you expect to find. That is often done by linear regression, though bioinformaticians often use simpler (naive Bayes) or more complicated (SVM regression, neural nets, hidden Markov models,…) ways of constructing the null model. People who use regression often forget to leave out the data for the point that they are testing, which distorts the results. Physicists tend to be particularly bad at that, because they are used to strong models where the model is much more believed than the data, and they have trouble dealing with fields where the models are weak as well as the data being noisy (like biology and sociology).
The approach I used here was a naive Bayes technique, as that is the easiest to explain and makes the assumptions very clear.
Comment by gasstationwithoutpumps — 2014 January 19 @ 11:07 |
I like the approach you’ve taken—mathematical statistics in place of the original propaganda statistics. I noticed, though, that your analysis says that only 4 of the 103 test takers in Utah were women right under a table showing Utah with 11 test takers. Is it possible that you inadvertently used the column showing number of schools offering the test as the number of test takers?
Comment by Glen — 2014 February 1 @ 13:33 |
Good eyes, Glen! I did indeed make copying errors transferring the numbers from the spreadsheet to the HTML table (two awful formats). I believe I have now corrected the post to get the numbers right. The conclusions do not change substantially, but it is embarrassing to have made so many copying errors.
Comment by gasstationwithoutpumps — 2014 February 1 @ 14:42 |
Our machines are designed for reliably transcribing lots of numbers; our brains aren’t.
Comment by Glen — 2014 February 2 @ 13:02 |
[…] Dept. of Education has made the AP CS exam its Poster Child for inequity in education (citing a viral-but-misinterpreted study). But ignored in all the hand-wringing over low AP CS enrollment is one huge barrier to the goal of […]
Pingback by Average HS Student Given Little Chance of AP CS Success | Learn By Doing — 2014 June 16 @ 09:47 |
[…] “What if learning to code weren’t actually the most important thing?” asks Mother Jones’ Tasneem Raja. “Rather than increasing the number of kids who can crank out thousands of lines of JavaScript, we first need to boost the number who understand what code can do.” Computational thinking, Raja explains, is what really matters. So, while Google is spending another $50 million (on top of an earlier $40 million) and pulling out all the stops in an effort to convince girls that code and AP Computer Science is a big deal, could AP Statistics actually be a better way to teach computational thinking to college credit-seeking high school students? Not only did AP Statistics enrollment surge as AP CS flat-lined, it was embraced equally by girls and boys. Statistics also offers plenty of coding opportunities to boot. And it teaches one how to correctly analyze AP CS enrollment data! […]
Pingback by Computational Thinking: AP Computer Science Vs AP Statistics? | Slash Dot Blog — 2014 June 27 @ 00:10 |