A common question that comes up for parents and teachers of high-school students is “How much test preparation is appropriate before taking the SAT or ACT tests?” The question is not an easy one to answer, as there are several related questions that are mixed together in often confusing ways.
- Do the tests really matter?
- Is it ethical to prepare for the SAT or ACT? Or should the exams be taken “cold”, like IQ tests?
- Does test preparation improve scores on the tests?
- What sort of test preparation is most effective?
- Is time and money spent on test preparation better invested in some other pursuit?
I’ll try to give my opinion on all these, backing it up with research results where I’m aware of any.
Do the tests really matter?
Newsweek recently published an article “Going SAT-Free” that reported on several top colleges no longer requiring SAT or ACT tests: “about 830 of the country’s 2,430 accredited four-year colleges do not use the SAT or ACT to admit the majority of applicants. (Some schools require a test if you have a low GPA or class rank.)”
That leaves about 2/3 of colleges (including most public colleges) still requiring either the SAT or the ACT. So students need to take the exam. How important a high score on the exam is depends on the specific college, but in general, higher scores will translate to a higher probability of getting in. (58% of colleges in one survey reported that the test scores were of considerable importance in admissions decisions.)
Is test prep ethical?
Some people have likened SAT tests to IQ tests, which present test takers with unfamiliar questions in order to determine how well they think. Preparing for an IQ test invalidates the test, rendering the resulting scores meaningless. Can the same be said for the SAT and ACT?
First, neither the SAT nor the ACT is attempting to measure IQ or other supposedly static properties of the test taker. They are intended to measure the student’s preparation for college work and predict how well they will do in college.
For achievement tests, the whole point of the test is to measure how much a student has learned—to measure the total learning that the student has acquired over several years. Preparation for achievement tests is essential, as what they are measuring is how well prepared the student is.
SAT and ACT tests are neither ability tests nor achievement tests, but a mix of the two concepts. They measure a combination of what the student knows (vocabulary, math concepts, and so forth) and how well they can solve simple puzzles using that knowledge. Given that the tests measure knowledge, it is not only ethical for students to prepare for the tests, but essential that they do so in some form.
The ethics question is then reduced to determining whether it is fair for wealthy students to spend more on preparing for the tests than poor students can. Since the best preparation for the exams is a good education for the preceding 10 years, it would be very difficult to eliminate the effects of wealth. Indeed, access to a superior education is one possible definition of wealth, independent of more conventional financial measures.
I can only conclude that preparing for the SAT and ACT tests is ethical.
Does test prep help?
The biggest debate seems to be about how coachable the SAT and ACT test scores are. There is little doubt that students who have had 10 years of excellent education do much better than students who have had 10 years of execrable education. The debatable question is whether short courses on content or coaching on test-taking techniques make any difference. There is a multibillion dollar test-preparation industry, so there is a lot of incentive for marketers to sell snake oil.
The best report I’ve found analyzing the actual effectiveness of test preparation is Derek C. Briggs’s paper Preparation for
College Admission Exams, published by the National Association of College Admission Counseling. It looks at all the published research on the topic and concludes that “Contrary to the claims made by many test preparation providers of large increases of 100 points or more on the SAT, research suggests that average gains are more in the neighborhood of 30 points.”
Of course, even just retaking a test, with no intervening coaching, can improve tests scores (on average about 15 points per section as reported by the College Board). This report on change in averages can be misleading, since students at the ends of the distribution are likely to move towards the middle on retaking (a phenomenon known as regression to the mean), so that top students should not expect any boost from retaking the test. Briggs estimates the “coaching effect”, how much bigger the gain is from coaching than from retaking the exam without coaching:
- Coaching has a positive effect on SAT performance, but the magnitude of the effect is small.
- The effect of coaching is larger on the math section of the exam (10–20 points) than it is for the critical reading section (5–10 points).
- There is mixed evidence with respect to the effect of coaching on ACT performance. Only two studies have been conducted. The most recent evidence indicates that only private tutoring has a small effect of 0.4 points on the math section of the exam.
Briggs later says “From a psychometric standpoint, when the average effects of coaching are attributed to individual students who have been coached, these effects cannot be distinguished from measurement error. … On the other hand, if marginal college admission decisions are made on the basis of very small differences in test scores, a small coaching effect might be practically significant after all.”
This raises the question of whether 20–30 points is going to make a difference in admissions decisions. Briggs looked at that question also. At the low end of the scale, a 20-point difference in SAT score would not affect admissions, but at the high end (600–750), 40% of surveyed college admissions officers thought a 20-point difference for math or a 10-point difference for critical reading would affect chances, but only 20% thought a 20-point difference for the writing section would change the probability of admission.
It appears that the effect of short-term test preparation is small, but that admissions officers are looking at differences in scores that are well below the noise level of the tests, so retaking tests in the hopes of getting a higher score randomly could be worthwhile, and test preparation could increase the chance of increasing one’s score enough to affect admissions decisions.
So it looks like doing some test prep may improve scores.
What sort of test prep is most helpful?
Of course, just because some test prep is worthwhile does not mean that any specific course is worthwhile. Briggs distinguishes between student-driven prep (using the example questions provided by the test publishers or studying content and doing sample tests from books) and coaching with a live teacher.
Briggs reports that “No forms of test preparation had statistically significant positive effects on SAT-V scores” and that books, courses, and tutors all had small positive effects on SAT-M. (Interestingly, use of a computer prep program had a small negative effect.)
Is test prep cost-effective?
Briggs says “Beyond that which occurs naturally during students’ years of schooling, the only free test preparation is no
test preparation at all. This is because all test preparation involves two costs: monetary cost and opportunity
cost.”
The financial costs are easy to analyze. Given the small gains from commercial coaching courses and the roughly similar gains from using a test prep book, there doesn’t seem to be much financial sense to paying for the much more expensive commercial courses. The books are cheap (and readily available from libraries) so there seems no financial barriers to using them.
The opportunity cost is the time spent on test prep that might more usefully have been spent studying for classes, sleeping, or doing extracurricular activities (like sports, theater, or community service). Here the analysis is more difficult, but I think favors spending fairly little time on test prep. Time spent pursuing a passion or serving the community is more likely to improve one’s chances of admission to college than small gains in test scores will. Of course, time wasted hanging out at the mall or playing video games is unlikely to have any positive effect.
What will we do?
Since my son did very well on the SAT math and critical reading sections when he took them in 6th grade (over 700), I see no reason for him to waste time on test prep for those sections. He did less well on the writing portion, getting the lowest possible score on the essay, but at the time he had never had instruction in timed essay writing, and had never even heard of the 5-paragraph essay so beloved of SAT graders. I expect that he will need little prep for the essay writing also, as he will undoubtedly get more practice on the 5-paragraph essay than any sane person could stand in his high school classes.

 , the probability of emitting character
, the probability of emitting character  in state
in state  , and
, and  , the probability of making a transition to state
, the probability of making a transition to state  from state
from state  ). It is common to refer to the parameters as a vector
). It is common to refer to the parameters as a vector 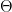 , so that we can concisely refer to functions of $\latex \Theta$. We have the constraints that
, so that we can concisely refer to functions of $\latex \Theta$. We have the constraints that 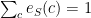 and $\latex \sum_T a_{ST} = 1$, that is that emission probabilities for a state
and $\latex \sum_T a_{ST} = 1$, that is that emission probabilities for a state 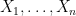 is the sum over all paths of length
is the sum over all paths of length  through the HMM of the probability of taking that path and emitting
through the HMM of the probability of taking that path and emitting  , that is
, that is 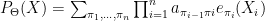 . The products are a bit messy to take derivatives of, because some of the parameters may be repeated, but we can simplify them by grouping together repeated factors:
. The products are a bit messy to take derivatives of, because some of the parameters may be repeated, but we can simplify them by grouping together repeated factors: ,
,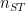 is the number of times
is the number of times  and
and 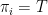 along a particular path and
along a particular path and 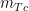 is the number of times
is the number of times 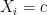 . Both of these new count variables are specific to a particular path, so should really have the
. Both of these new count variables are specific to a particular path, so should really have the  vector as subscripts, but we’ve got too many subscripts already.
vector as subscripts, but we’ve got too many subscripts already. for the constraints on the emission table of state
for the constraints on the emission table of state  for the constraints on the transitions out of state
for the constraints on the transitions out of state 

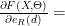

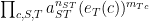
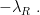
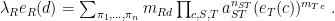
 produces character $d$. Note that this happens only for positions
produces character $d$. Note that this happens only for positions  where
where  , so we can rewrite it as the sum over all such positions of the probability of being in state
, so we can rewrite it as the sum over all such positions of the probability of being in state 
 , by adding all these equations:
, by adding all these equations:
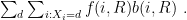





")
 or hardback ($198)")

