One of programmers I work with asked me for a write-up or source code for a careful implementation of sum of probabilities in log-prob representation. I lecture on the topic at least once a year, but the talks are always extemporaneous white-board talks, so I don’t have any written notes. I’m sure I’ve written it up carefully at some point in the past, but after an hour I was unable to find either well-written code or a good written description of the method, so I gave up looking and decided to redo the derivation on my blog (where, I hope, I can find it again).
The problem is mathematically very simple. We have two non-negative numbers (usually probabilities), p and q, that are represented in the computer by floating-point numbers for their natural logs: 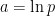
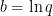

The brute-force way to do this in code is log(exp(a) + exp(b)), but this can run into floating-point problems (underflow, overflow, or loss of precision). It is also fairly expensive, as it involves computing three transcendental functions (2 exponentiation and 1 logarithm).
We can simplify the problem: 
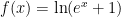

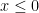
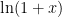
But we can still run into problems. If x is very negative, then exp(x) could underflow to 0. This is not a serious problem, unless the programming language treats that as an exception and throws an error. We can avoid this problem by setting a threshold, below which the implementation of f just returns 0. The threshold should be set at the most negative value of x for which exp(x) still returns a normal floating-point number: that is, the natural log of the smallest normalized number, which depends on the precision. For the IEEE standard floating-point representations, I believe that the smallest normalized numbers are
| representation | smallest positive float | approx ln |
|---|---|---|
| float16 | 2-15 | -10.397207708 |
| float32 | 2-127 | -88.029691931 |
| float64 | 2-1023 | -709.089565713 |
| float128 | 2-16383 | -11355.8302591 |
By adding one test for the threshold (appropriately chosen for the precision of floating-point number used in the log-prob representation), and returning 0 from f when below the threshold, we can avoid underflowing on the computation of the exponential.
I was going to write up the choice of a slightly higher cutpoint, where we could use the Taylor expansion 
inline float log1pexp(float x)
{ return x<-88.029691931? 0.: log1p(exp(x));
}
inline float sum_log_prob(float a, float b)
{ return a>b? a+log1pexp(b-a): b+log1pexp(a-b);
}
inline double log1pexp(double x)
{ return x<-709.089565713? 0.: log1p(exp(x));
}
inline double sum_log_prob(double a, double b)
{ return a>b? a+log1pexp(b-a): b+log1pexp(a-b);
}
inline long double log1pexp(long double x)
{ return x<-11355.8302591? 0.: log1p(exp(x));
}
inline long double sum_log_prob(long double a, long double b)
{ return a>b? a+log1pexp(b-a): b+log1pexp(a-b);
}
A careful coder would check exactly where the exp(x) computation underflows, rather than relying on the theoretical estimates made here, as there could be implementation-dependent details that cause underflow at a higher threshold than strictly necessary.

")
 or hardback ($198)")


This was pretty cool!Very clear.
Comment by xykademiqz — 2014 May 12 @ 05:17 |
Is there any optimizations for summing n probabilities. For example using this n times would use n log and exp calls. Is it possible to avoid this?
Comment by brugel — 2015 April 10 @ 20:05 |
I don’t know of a simplification for n additions, since factoring out one term would still leave n-1 of them. One could probably speed things up substantially by replacing the log and exp calls by an approximation algorithm for log(1+exp(x)), perhaps using CORDIC techniques.
Comment by gasstationwithoutpumps — 2015 April 10 @ 20:13 |
[…] Sum of probabilities in log-prob space […]
Pingback by Spike in views on Monday | Gas station without pumps — 2017 September 22 @ 12:06 |
[…] Sum of probabilities in log-prob space […]
Pingback by Blog stats for 2017 | Gas station without pumps — 2018 January 1 @ 11:47 |
I’ve written a simple and easy function in python to do the same task. It takes in ‘a’ and ‘b’ as floats in log space, and returns their values added together. Great for adding together probabilities in log space.
from numpy import log1p
def sumLogProb(a,b):
if a > b:
return a + log1p(exp(b-a))
else:
return b + log1p(exp(a-b))
Comment by EzraCornell — 2018 December 6 @ 20:11 |
The computation you do has an exponential followed by a log computation, so it is a fairly expensive way to handle the problem.
Comment by gasstationwithoutpumps — 2018 December 6 @ 21:04 |